HL7中国批量数据导出服务实施指南
2026.01.23 - release
HL7中国批量数据导出服务实施指南
2026.01.23 - release
HL7中国批量数据导出服务实施指南 - Local Development build (v2026.01.23) built by the FHIR (HL7® FHIR® Standard) Build Tools. See the Directory of published versions
定义了一套标准化的、基于FHIR的异步操作,用于从资源服务器向授权客户端高效导出大规模医疗数据集。它旨在解决传统FHIR API在处理海量数据时面临的性能瓶颈,并简化跨系统的批量数据交换流程。
传统的医疗数据批量交换流程繁琐,涉及数据提取、格式转换和文件传输等多个步骤,成本高昂。现有的FHIR API适合处理实时、小规模的数据交互,但对于需要导出数十万条记录的场景(如用于研究或质量评估的患者队列数据),发起大量请求是不现实的。本实施指南通过定义标准的$export操作,使客户端能够以异步方式一次性请求并获取特定群体(如所有患者、一组患者或系统全部数据)的大量资源,服务器会将结果生成为NDJSON格式的文件供客户端下载。
本实施指南是在Bulk Data Access IG v3.0.0的基础上进行剪裁,以适应中国医疗卫生领域的数据交换环境以及HL7中国的FHIR Connectathon评估要求。
本实施指南旨在供后端服务(客户端)和资源服务器(如HIS系统、EMR系统、数据仓库等)开发者使用。这些开发者旨在通过共享大型FHIR数据集实现互操作。本指南定义了服务接口,客户端可以通过这些接口向服务器请求批量数据导出、接收关于导出文件进展的状态信息,并检索这些导出文件。
本实施指南范围不包括:
为了声明符合该实施指南,服务器应在CapabilityStatement.instantiates中包含以下URL:
http://hl7.org/fhir/uv/bulkdata/CapabilityStatement/bulk-data
本实施指南旨在支持共享任何可在FHIR中表示的数据。这意味着本实施指南应适用于如下系统:
本实施指南基于FHIR 异步请求模式 ,并在某些地方可能会扩展该模式。
批量数据导出服务主要涉及两个角色:
批量数据导出服务的交易图如下所示:
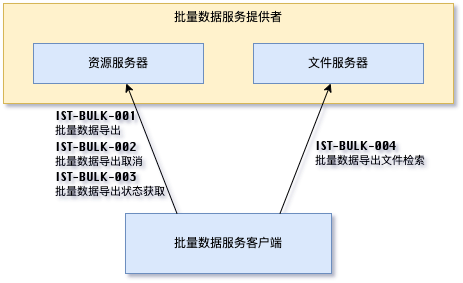
批量数据导出服务的交易如下:
批量数据导出服务的时序图如下所示:
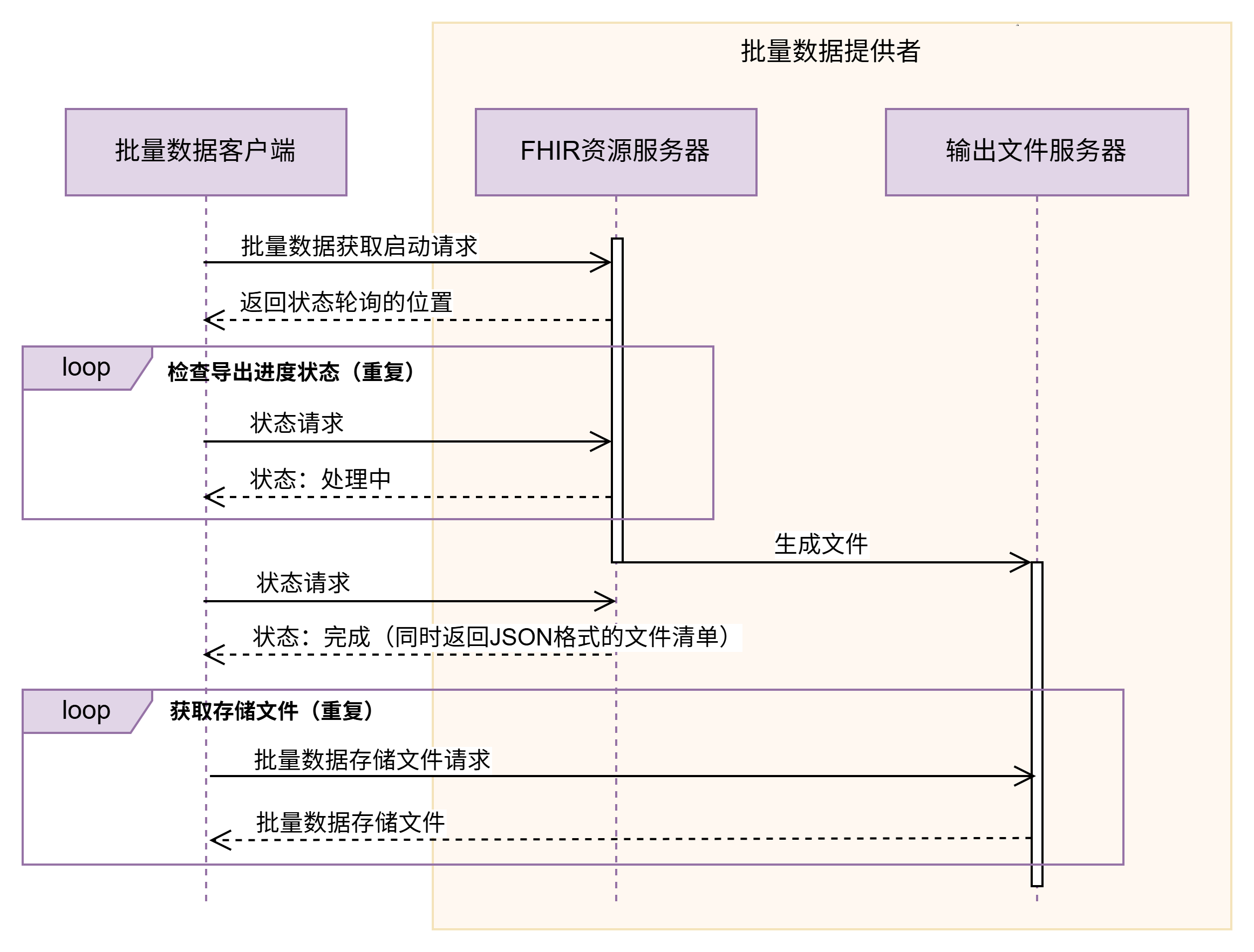
PHI。Expires来限制客户端下载文件的时间区间(文件从服务器移除由服务器实现者决定)。如果客户端正在下载文件,那么服务器就不应删除正在下载的文件,无论文件是否过期。